No products in the cart.
4. Data a informace
Data jsou naprosto klíčovou ingrediencí umělé inteligence, a proto je třeba jim při návrhu inteligentních systémů věnovat náležitou pozornost. Schopnost porozumět datům a správně je interpretovat je však důležitá nejen pro programátory. Jedná se o zásadní dovednost pro všechny, kteří chtějí uspět v datově orientovaném světě 21. století.
Před tím, než začneme pracovat s daty, bude dobré rozlišit dva často zaměňované pojmy, kterými jsou data a informace. Data jsou soubory údajů, popisující objekty nebo události. Může se jednat o čísla, text, obrázky apod. Pokud dostanou data nějakou strukturu, můžeme je nazvat datovou množinou (anglicky data set). Informace jsou data doplněná o význam a kontext.
Pro ilustraci si uveďme několik příkladů:
- 1603, 1492, 1324 jsou číselná data. Když doplníme, že se jedná o nadmořské výšky Sněžky, Pradědu a Lysé hory v metrech, dostaneme informaci.
- (255, 245, 135), (255, 55, 67), (98, 52, 64), …
Dalším příkladem dat je posloupnost trojic čísel. Jestliže se dozvíme, že každá trojice reprezentuje jeden pixel v obrázku slona, dostaneme informaci. - 6d e1 6d 61 20 6d 65 6c 65 20 6d 61 73 6f
Posloupnost bajtů v šestnáctkové soustavě je jiný příklad dat. Pokud doplníme, že je máme interpretovat jako písmena, dostaneme text “máma mele maso”, což je již informace.
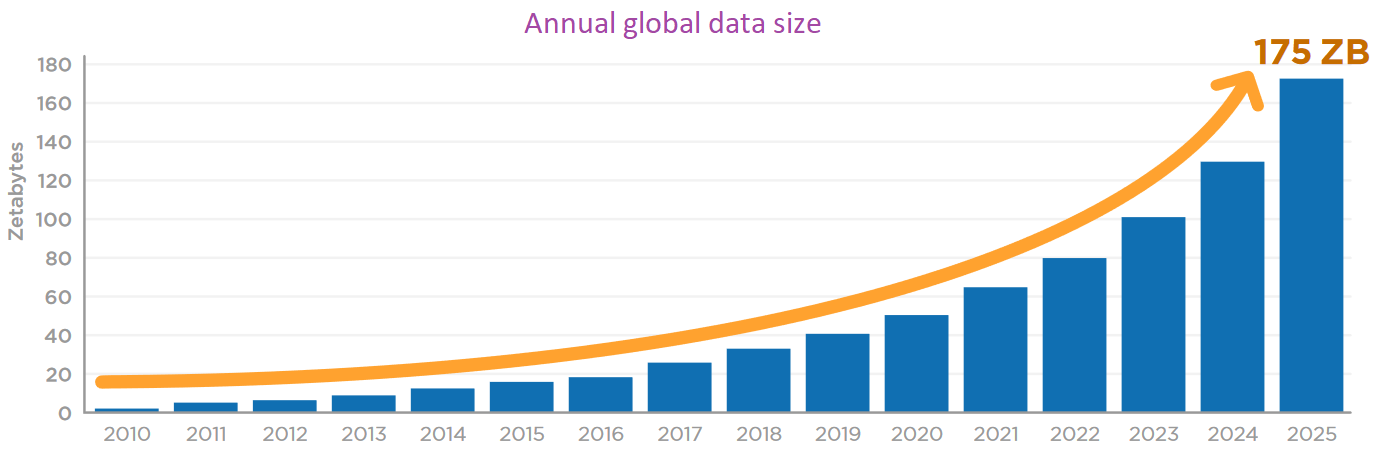
Obrázek 1: Exponenciální rychlost růstu dat v elektronické podobě.
Způsoby vzniku dat
Pro použití dat v nástrojích umělé inteligence je důležité, aby byla data k dispozici v elektronické podobě. Do té je možné data převést transformací z jiných forem (například přepisem papírových knih), ale mnohem častější je dnes situace, kdy data vznikají přímo v elektronické podobě. Nejčastější způsoby vzniku data uvádíme níže.
Přirozený vznik – největší množství dat v elektronické podobně dnes vzniká přirozeně. Kdykoliv někdo napíše komentář na internetu, pořídí fotografii mobilním telefonem nebo třeba jen klikne kurzorem myši na produkt v internetovém obchodě, vytvoří tak datový záznam. To se mnohdy děje i bez vědomí uživatele.
Měření a snímání – sem spadá použití všech hardwarových nástrojů, které jsou schopné zaznamenávat údaje ze svých čidel. Může se jednat o audiovizuální záznamy z diktafonů, kamer nebo mobilních telefonů, měření tepové frekvence pomocí chytrých hodinek či bederního pásu. Jiným příkladem je třeba domácí meteorologická stanice, která ukládá data o teplotě, vlhkosti vzduchu a atmosférického tlaku do cloudu.
Ruční tvorba – velice často není možné sbírat data automaticky a je třeba k tomu využít ruční práce. Jedná se například o ruční přepis papírových dokumentů, ruční vyznačení objektů na obrázku nebo ohodnocení relevance dokumentu vůči dotazu v internetovém vyhledávači.
Průzkumy – zejména pro výzkum různých sociologických jevů se velice často používají průzkumy, tedy sběr dat cíleným oslovováním lidí. Patří sem například průzkumy volebních preferencí, zjišťování názorů lidí na různá témata, ale třeba i uživatelská hodnocení produktů.
Generování – jedná se poměrně nový způsob vytváření dat, při kterém jsou data generována algoritmicky, často s využitím umělé inteligence. Můžeme sem zařadit automatické roboty generující textové příspěvky na Twitteru nebo v internetových diskuzních fórech, ale v poslední době i nástroje, umožňující generovat či modifikovat audiovizuální záznamy a vytvářet tím takzvané deep fakes.
Otevřená data
Otevřená datajsou snadno dostupná a strojově čitelná data, zveřejněná na internetu. Důvodem zveřejnění je často veřejné dobro. Pravidla jejich použití jsou proto co nejvolnější a jasně definovaná. Hlavními poskytovateli veřejných dat jsou z principu veřejné instituce, které to v některých případem mají i nakázané zákonem. Přehled dostupných otevřených dat státní správy lze nalézt například na webu https://data.gov.cz/. Rozhodně se však nejedná o vyčerpávající a jediný zdroj otevřených dat v ČR. Jednotná databáze však zatím bohužel neexistuje.
Strukturovaná a nestrukturovaná data
Z pohledu obtížnosti strojového zpracování můžeme data rozdělit na strukturovaná a nestrukturovaná. Strukturovaná data jsou taková, která mají jasnou logickou strukturu a dají se tak snadno zpracovat nebo rozřadit. Jedná se například o tabulky v databázích, záznamy v buňkách Excelu, strukturované formáty souborů jako CSV apod. Nestrukturovaná data naopak snadné strojové zpracování neumožňují. Přestože jsou pro člověka typicky jednoduše srozumitelná, pro počítačové porozumění představují problém. Jako příklady nestrukturovaných dat můžeme uvést obrázky, videa nebo texty. Zpracování a porozumění nestrukturovaným datům je často úlohou systémů umělé inteligence.
Big data
V poslední době jsou velká data (angl. big data) často skloňovaný pojem, nejedná se však o nic jiného, než o velké objemy dat a data setů, které byly dříve (zhruba před rokem 2000) spíše ojedinělé. Pro velká data je charakteristické, že se nevejdou na jeden počítač, a proto je třeba je distribuovat mezi více počítačů. K tomu se používají takzvané počítačové klastry. Z faktu, že data nejsou uložena pouze v jednom počítači vyplývá i jiný způsob jejich zpracování. K tomu se používají techniky distribuovaného zpracování dat jako Map-Reduce a specializované nástroje jako např. Hadoop.